Telegram Bot Markov Chains
Last semester, I took an “Introduction to Computational Linguistics” class.
It offered a survey of various topics in computational linguistics, such as part of speech tagging and machine translation, and a couple of simple projects to get your feet wet with the field. It was absolutely an introductory course, and I enjoyed it! Though to some extent I regret not taking the security course instead, but I’ll take that soon : )
The course involved a final project. The default option was a sentiment classifier using the WEKA toolkit, but I wasn’t super enthused about it, since it’d mean futzing with the kinda-crappy Java application for 10-20 hours.
I’ve built a couple of bots for the Telegram instant messenger (which I wouldn’t really recommend), so I have a bit of familiarity with the well-maintained Python bot library. I’ve also set up (but since stopped hosting) simple twitter markov chain bots for friends.
Performance evaluation is a big part of computational linguistics, so I figured I might be able to come up with something fun. I asked my professor if I could do some kind of markov chain-on-text implementation similar to existing ebooks bots, and then evaluate its performance against real text.
Also, this seemed like a great excuse to do some statistics work on my chats. I’m interested in measuring just how much I communicate.
She approved the idea, and I thought up of a system for testing my implementation against others. I wanted to make it slightly game-like, so that my friends would have fun generating data for me.
I dumped my entire Telegram chat history using the command line Telegram interface and some Ruby scripts for the purpose. I decided to use only messages from my primary groupchat.
I googled for some existing markov chain text-generation code online, and sat for a while trying to understand it. Markov chain text generation works by basically building large lists of word pairs called bigrams, randomly selecting a start word, and then building a sentences selecting following words from your word pairs. I found some libraries, and wrote a bit of my code adding start and end tags to my input corpus. I ran the text-generating code against all of the messages that I’ve sent to xFF5353, our college friend group chat.
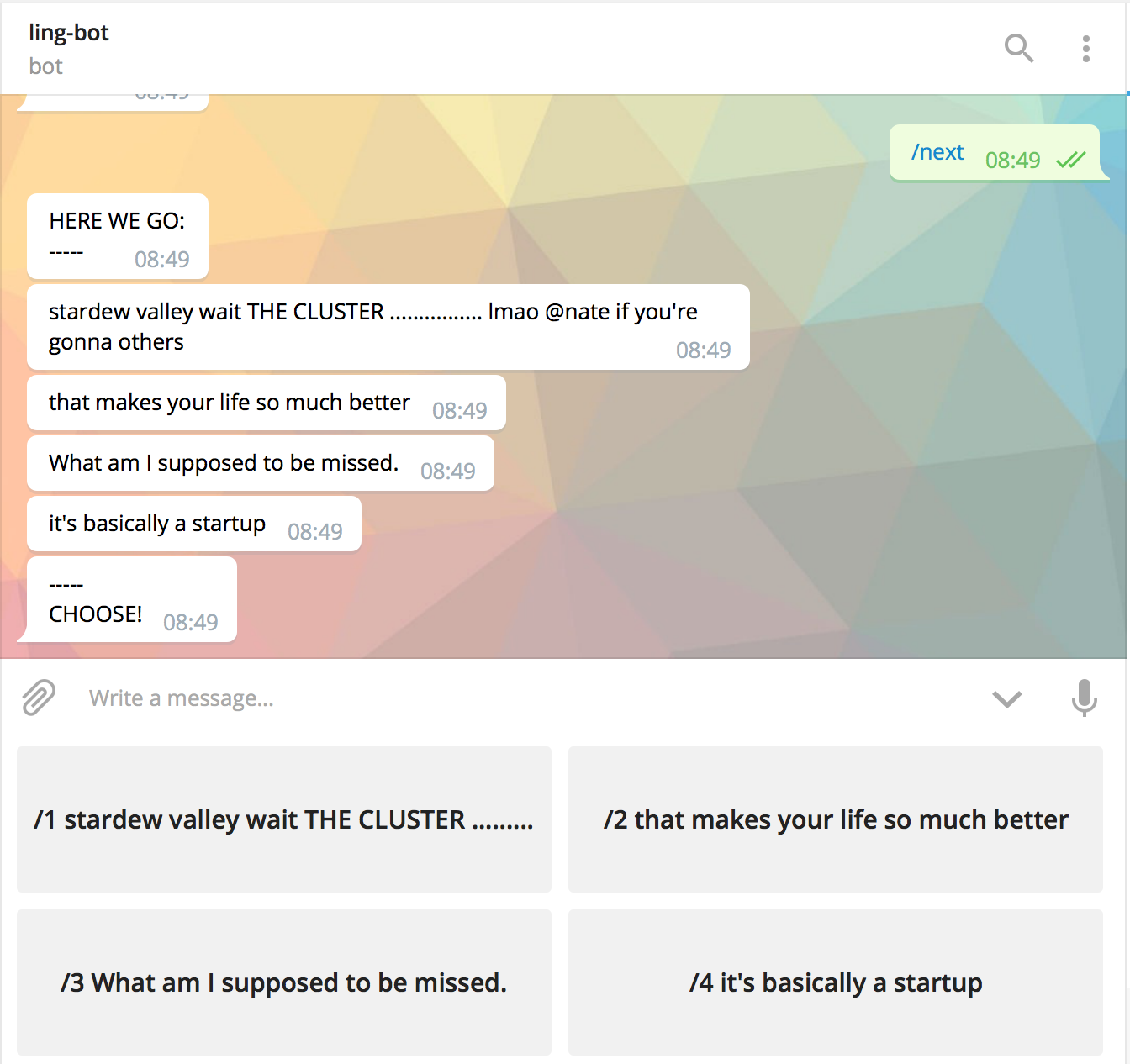
I then built a bot that would present four options to a user. Their goal was to pick which of the four was real text, where the other three were generated by a different markov chain implementation. I would then evaluate which of the implementations was most commonly thought to be real — “best”.
I have a very… distinct messaging style — I’ll often break longer messages with multiple newlines. It’s the sort of behavior that’d get me yelled at in a busy chatroom, but is typically fine in a small groupchat. My messaging style worked to the benefit of the markov chains, though, in that my messages out of context were often as nonsensical as the generated ones.
I asked most of my friends with Telegram accounts to play the bot game for a while, so that I’d have enough data to draw meaningful conclusions. I promised food to the person who guessed the most accurately (though friends who were in the groupchat had an advantage in having seen the real messages before). It was fun watching all the data come in (I ranked my friends on a leaderboard that only I could see), and I’m very relieved that I didn’t have to worry about any sort of synchronization problems with simultaneous users. For players with >=50 submissions (which was the baseline to be considered for food) the best player had about a 66% correct rate - the worst, around 40% (in the repo, data/count-best-player.py).
I was surprised by the final data counts. Of 1371 submitted answers, 737 were correctly selected, 366 were my implementation, and 126 and 52 were attributed to the more naive implementations from existing libraries. Um, those don’t add up to 1371, so I think there was a small error rate — likely in bot usage bugs (say, from double-tapping a response button) or errors that I try: except’d away in Python. Still, my implementation did far better than I was expecting, which was very pleasing! I suspect that it’s because of the start/end tags making more believeable, and shorter, snippets of text. The other implementations would simply read all the messages in as a very long block, without respect for newlines — so they often created messages that were clearly ridiculous and not real.
The bot’s still running at t.me/ling_406_bot, but I have no idea how long I’m gonna keep the AWS instance up. I’ve posted all the code to Github, so you can take a look/run it yourself if you’re interested. My favorite part is probably the readme doc, which has a nice explanation of my approach and some analysis on the data.